
A Machine Learning glossary






Machine Learning glossary: some false friends in Earth Observation and Computer Vision
Quick introduction
If you are an expert in Earth Observation (EO) and you would like to apply the latest methodologies of Machine Learning like Deep Convolutional Neural Network to carry-out EO analysis in a data driven approach, or if you are an expert in Artificial Intelligence and you would like to apply your knowledge in Computer Vision in a Remote Sensing domain, you might want to make sure that you have the correct meaning of some words in mind when you migrate from one domain to another.
Beware of false friends
#1 CLASSIFICATION
One of the first differences in wording I have noticed is related to the word classification: in Computer Vision the word classification includes the type of Supervised Learning problems which has classes (e.g. good, bad) as output type. This includes different types of sub-categories:
- Image Classification: the model predicts if a certain class (e.g. cat, dog etc) is present in the picture
- Object Detection: the model predicts if a certain class (e.g. cat, dog etc) is present in the picture and where it is located (e.g. Bounding box and location)
- Image Segmentation: the model predicts for each pixel in the image the class that it belongs to

In Earth Observation the term classification includes a set of different products like Land cover or Land Use. An example of this is the Corine Land cover in Figure 2.
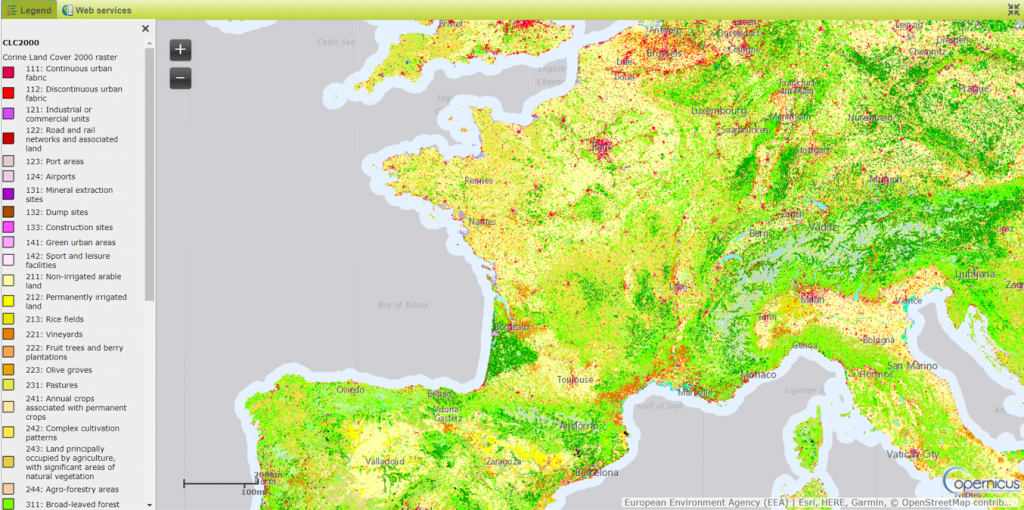
As you can see those types of EO products are the equivalent of an image segmentation in the computer vision domain but the wording in EO comes from the objective of map which is actually to classify –in this case- the different type of Land Cover.
#2 VALIDATION DATASET
Another element of misalignment which I have noticed sometimes between EO experts and Computer Vision experts is related to the usage of the term validation datasets.
In Computer Vision or more generically in Computer Science, the standard approach in Supervised Machine Learning is to split the dataset in Training, Validation and Test sets. Where:
- Training Dataset: The sample of data used to fit the model.
- Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration.
- Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
On top of this, once the model is transferred to a production/operational chain, it is important to evaluate its performance also there.
In my experience, the meaning that the Earth Observation domain associates to the term “validation” is inherited more from the software engineering field where the validation process aims to verify that the system is doing the “right thing” and not just the “things right”.
The validation process includes also the data collection and data evaluation, from the process design stage and throughout production, which establishes scientific evidence that a process is capable of consistently delivering quality products. That’s why also in the Earth Observation domain you can hear about validation campaigns which aim to verify that a sensor in space is working as expected and it is generating data consistent with the model.
So you can imagine what kind of misunderstandings can be generated in a discussion where an EO expert is asking a Machine Learning expert: “do you have a validation dataset?”.
#3 TRAINING DATA SET
Last but not least, I have noticed in several conversations an improper usage of the wording “training dataset” in the EO domain. Sometimes EO experts refer to ground truth data, information collected on the Earth in a certain location (e.g. a national forestry inventory), as training dataset, while in the Machine Learning domain, training dataset is intended to mean the joint input / expected output, one to one association. This has on several occasions created a non-trivial misunderstanding/ambiguity because one thing is to start a Machine Learning project with/while in possession of a training dataset, and another is to start a project where you have to build it.
I would also like to raise awareness –to the AI experts- of the high probability of misalignment between ground truth data and remote acquisitions which should not be underestimated when planning to build a dataset. To give you the simplest example, imagine that you have a map (a ground truth map) of an area after a fire and that you want to use this to build a training dataset with EO data. Your aim will be to train a model which will then be able to automate (in computer vision I would have to say “predict” but this might be misleading for an EO expert here J ) the mapping of burned areas but, e.g. if you use an optical sensor, you might have cloud in that area.
This, the association of data to value (input/ expected output), required an enormous effort in the generation of the ImageNet dataset which was one of the enablers of the AI revolution we are witnessing in these years. On the other side the objective of remote sensing goes beyond simple image classification or segmentation or object detection (think about snow-water equivalent or biomass estimation) which require a level of expertise that cannot be delegated to the crowd -as we generally say, It’s not a cat/dog problem-. Because of this, I personally believe that the EO domain offers to the AI community great challenges and I am looking forward to seeing how this cooperation will grow in the future.
Conclusion
I only have one recommendation in this particular case which is applicable to any communication context but much more when different domains meet each other: “Do not take anything for granted!”, ask , make sure there is a common understanding and share your knowledge!
Post contributed by Alessandro Marin.